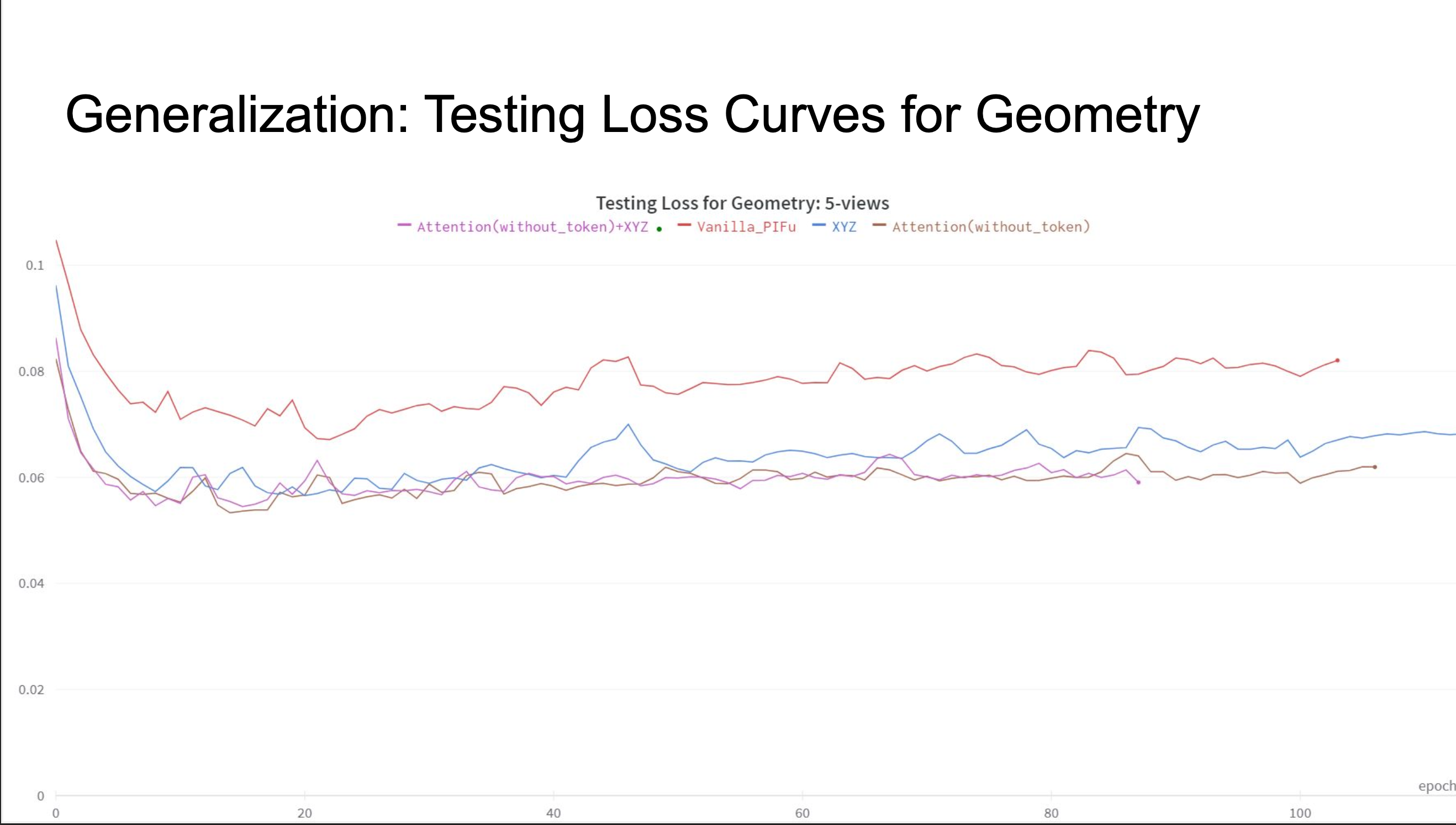
Objective
To design and implement a robust deep learning framework for 3D dynamic scene reconstruction, leveraging multi-view camera systems, to model complex human interactions in densely populated environments.
Dataset

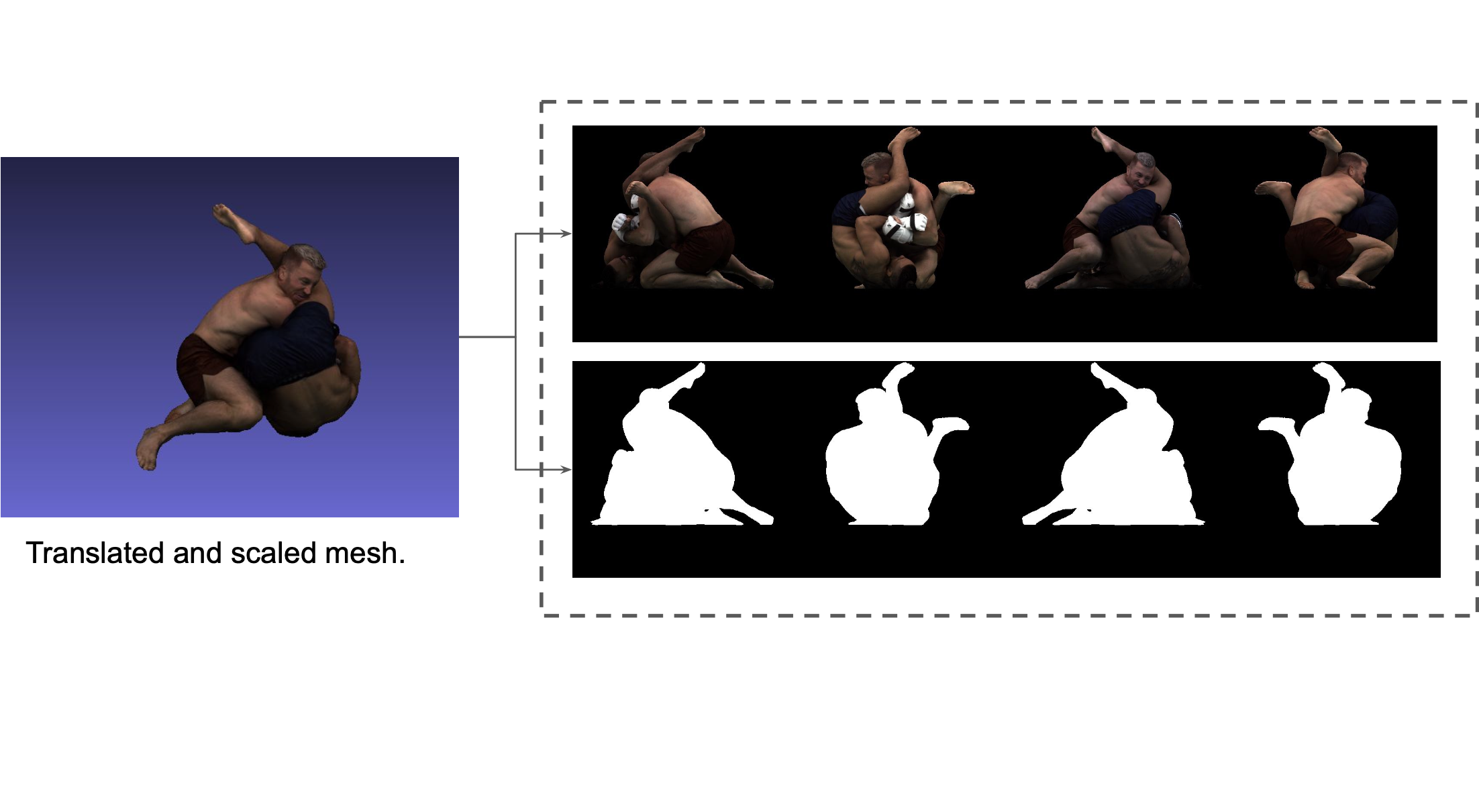
UFC Dataset
Result Demonstration


Prediction on a unseen scene
Method
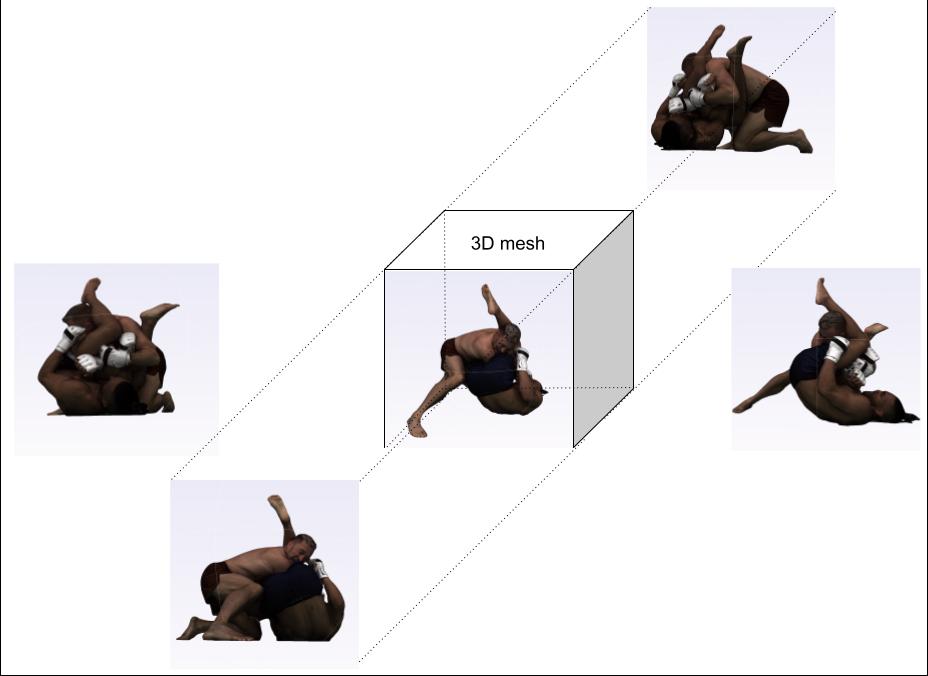
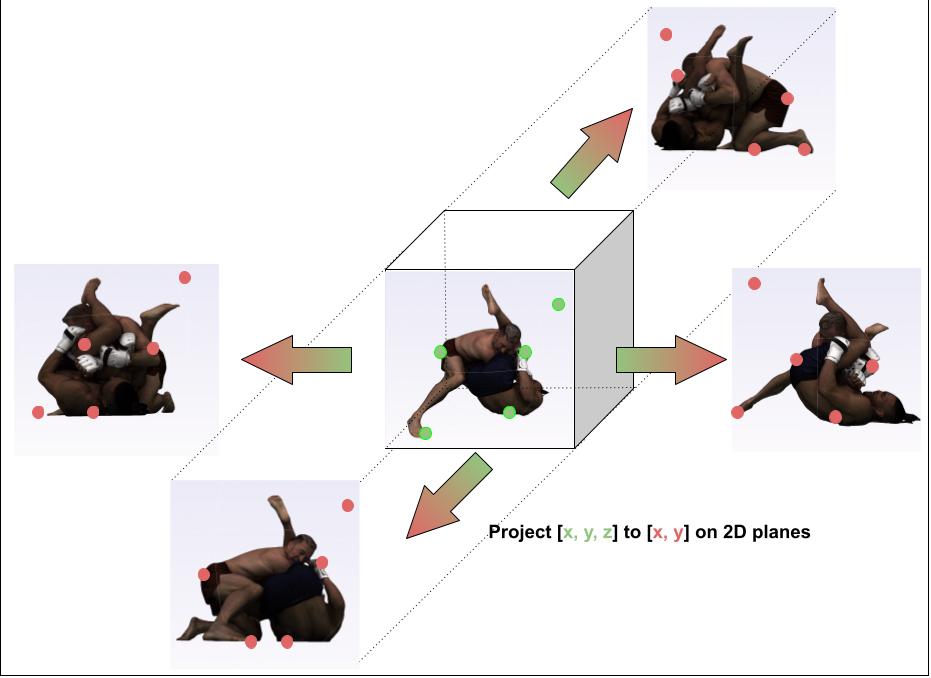
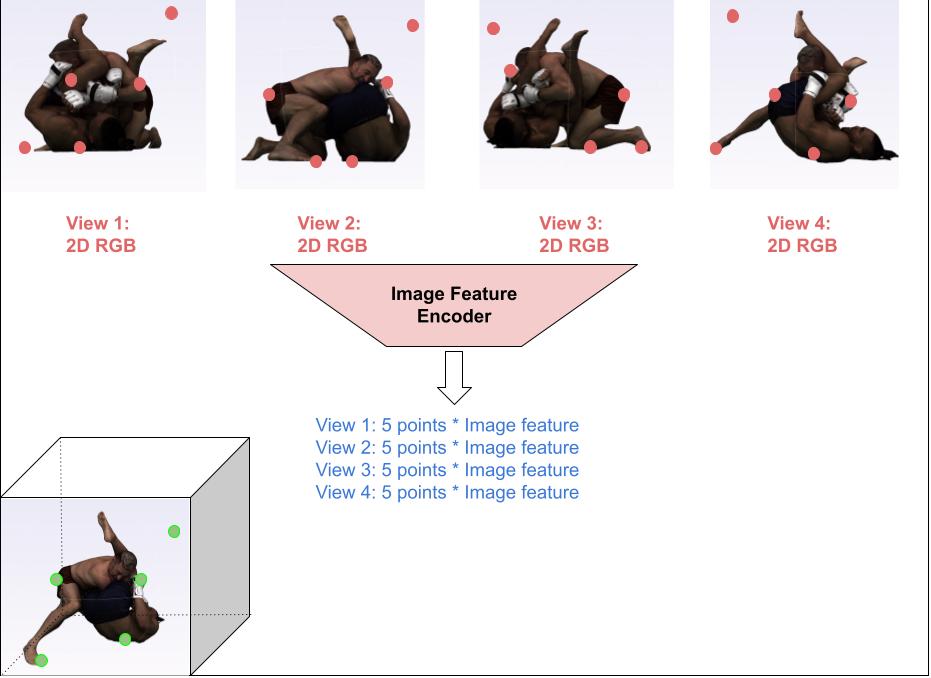
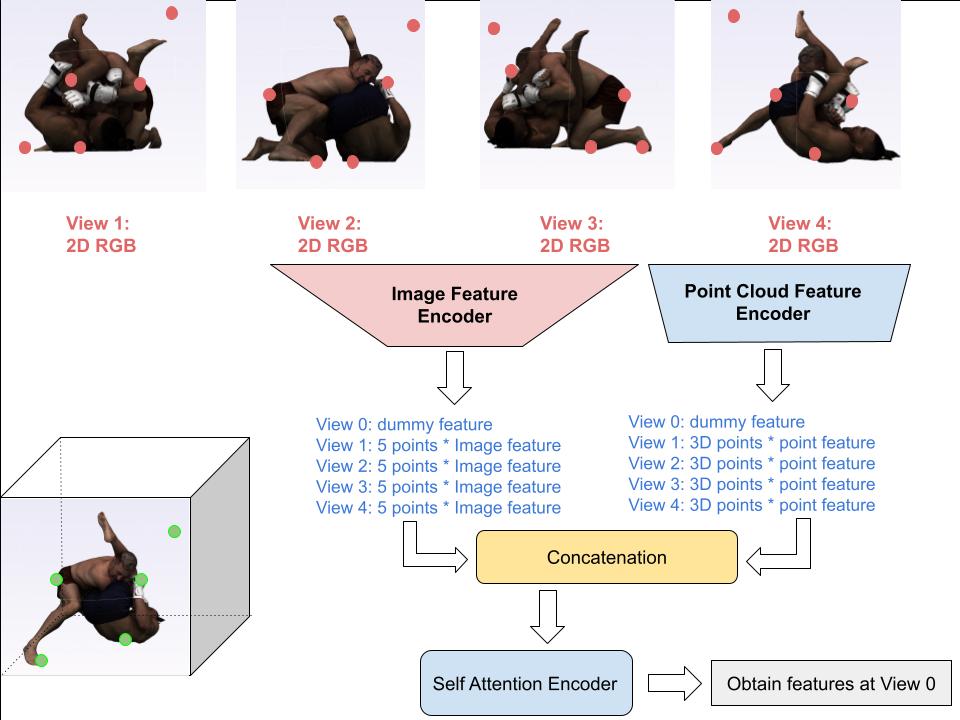
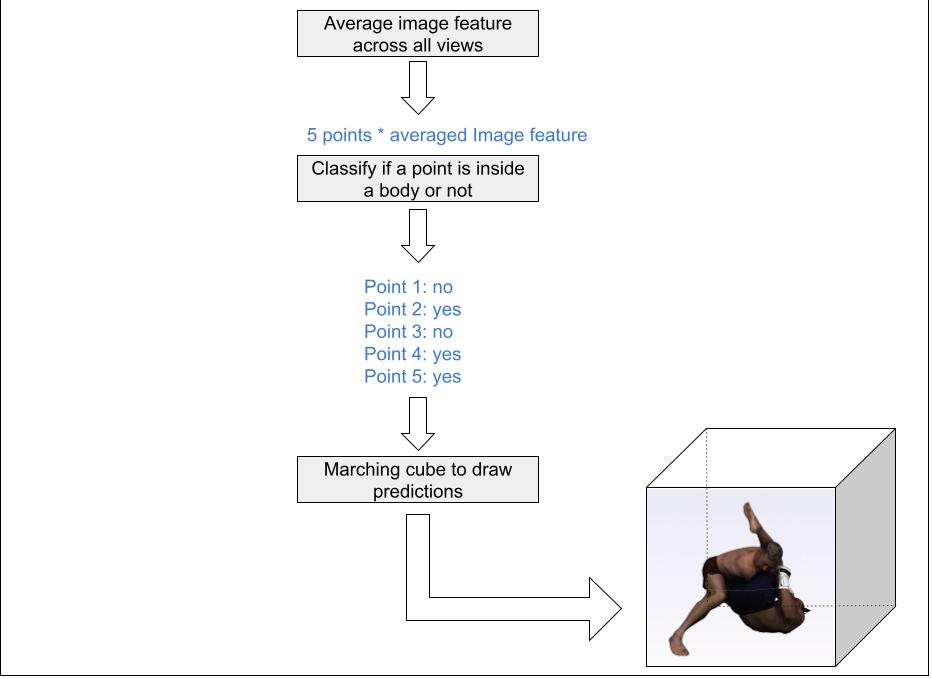
The following diagrams illustrate the geometry branch of our model.

Experiments